
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- webserving
- 캐글
- Kaggle
- ml 웹서빙
- streamlit
- 머신러닝
- DASH
- 공간시각화
- qgis
- dl
- K최근접이웃
- pytorch
- fastapi
- KNN
- 딥러닝
- 성능
- 2유형
- 1유형
- Ai
- 빅데이터분석기사
- CUDA
- GPU
- 3유형
- 인공지능
- gradio
- 공간분석
- 예제소스
- 실기
- ㅂ
- QGIS설치
Archives
- Today
- Total
에코프로.AI
[Python] RNN 구현 (Feat. Tensorflow) 본문
[머신러닝] RNN(Recurrent Neural Network)
RNN 이란?RNN(Recurrent Neural Networks)은 순차적 데이터를 분석하기 위한 딥러닝 모델입니다. DNN(Deep Neural Network)은 은닉층 내 노드간에 연결이 안되어 있지만, RNN은 은닉층 내 노드를 연결하여, 이전 스
www.ecopro.ai
구현관련 설명
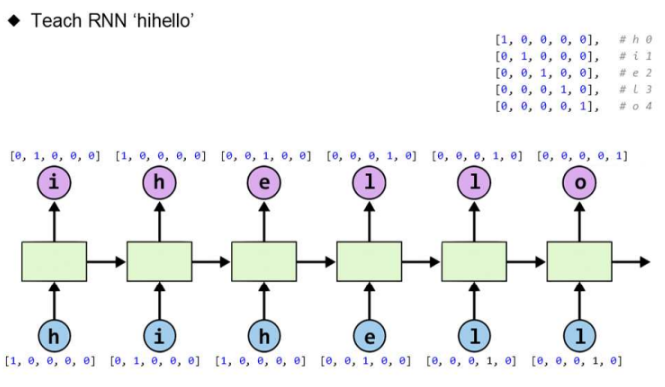
전체 7자리인 "hihello" 문자열의, 앞 6자리를 독립변수(x_data)로 뒤 6자리를 종속변수(y_data)로 RNN 모델링을 하여, 입력한 문자 다음 문자를 예측하는 모델을 구현
Ex)
입력 → 출력
'h' → 'i'
'i' → 'h'
'h' → 'e'
'e' → 'l'
'l' → 'l'
'l' → 'o'

RNN 코드 구현
데이터 준비 및 전처리
- 예측할 문자열 선언
text = 'hihello'
- 문자열의 unique(유일한) 문자 구분
- 'h', 'l'은 중복으로 1개씩 제외 됨.
idx2char = ['h', 'i', 'e', 'l', 'o']
idx2char
- "hihello" 단어의 각 문자별, idx2char 리스트의 인덱스위치 값 가져오기
data = [idx2char.index(ch) for ch in text]
print(data) # hihello
- 원핫 인코딩
from tensorflow.keras.utils import to_categorical
one_hot = to_categorical(data)
one_hot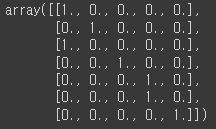
- RNN은 input으로 3차원 텐서만 입력받을 수 있습니다.
- np.newaxis 사용해서 3차원으로 변경
import numpy as np
x_data = one_hot[:-1][np.newaxis,:,:] # hihell
y_data = one_hot[1:][np.newaxis,:,:] # ihello
print(x_data.shape, y_data.shape)
x_data # hihell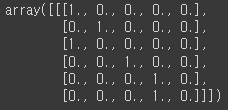
y_data # ihello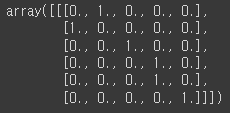
데이터 모델링 (SimpleRNN)
모델링
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Conv2D, MaxPool2D, Flatten, Dense, Dropout
from tensorflow.keras.layers import SimpleRNN
model = Sequential()
# 6 : 시퀀스(문자)의 길이 "hihell"
# 5 : 속성의 개수(문자의 유니크한 값) ['h', 'i', 'e', 'l', 'o']
model.add(Input(shape=(6, 5)))
# return_sequences : 각 셀의 출력값을 유효하게 리턴 요청
model.add(SimpleRNN(16, return_sequences = True))
# 출력값 : 5개, 활성화함수 : 'softmax'
model.add(Dense(5, activation = 'softmax'))
model.summary()
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
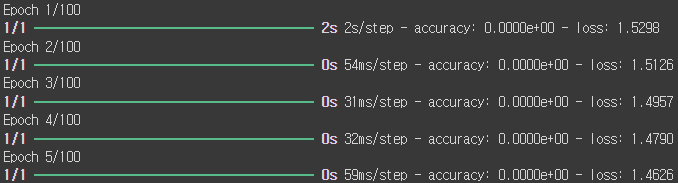
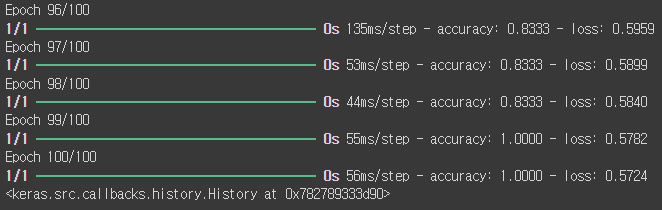
model.fit(x_data, y_data, epochs = 100)
예측
전체 입력 데이터(x_data) 예측
pred = model.predict(x_data)
pred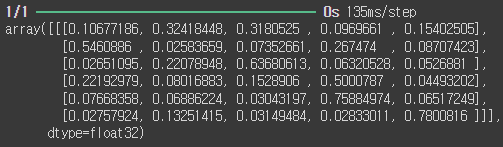
각각 가장 높은 배열 위치 가져오기
np.argmax(pred, axis = -1)
입력 된 다음의 데이터를 정확하게 예측했습니다.
argmax_pred = np.argmax(pred, axis = -1)
for i_cnt, i in enumerate(argmax_pred[0]):
print(list(text)[i_cnt] + ' : ' + idx2char[i])
끝~

'AI Tutorial' 카테고리의 다른 글
| [Python] 전이학습(Transfer Learning) 설명 (0) | 2024.08.29 |
|---|---|
| [Python] 오토인코더(AutoEncoder) 설명 및 코드구현 (Feat. Tensorflow) (1) | 2024.08.28 |
| [Python] CNN 구현 (Feat. Tensorflow) (0) | 2024.08.27 |
| [머신러닝] RNN(Recurrent Neural Network) (0) | 2024.08.26 |
| [머신러닝] CNN(Convolutional Neural Network) (0) | 2024.08.23 |
'AI Tutorial' Related Articles
more



