
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 공간시각화
- 캐글
- 인공지능
- 예제소스
- dl
- QGIS설치
- fastapi
- GPU
- pytorch
- Kaggle
- streamlit
- 공간분석
- CUDA
- 실기
- 2유형
- ml 웹서빙
- 빅데이터분석기사
- 3유형
- qgis
- DASH
- 딥러닝
- 성능
- 1유형
- webserving
- ㅂ
- gradio
- K최근접이웃
- 머신러닝
- Ai
- KNN
- Today
- Total
에코프로.AI
[텍스트마이닝] 감성분석-네이버 영화리뷰 본문
참고자료 : 네이버 영화 리뷰 감성 분류하기
참고사이트 : https://wikidocs.net/44249
이번에 사용할 데이터는 네이버 영화 리뷰 데이터입니다.
총 200,000개 리뷰로 구성된 데이터로 영화 리뷰에 대한 텍스트와
해당 리뷰가 긍정인 경우 1, 부정인 경우 0을 표시한 레이블로 구성되어져 있습니다.
해당 데이터를 다운로드 받아 감성 분류를 수행하는 모델을 만들어보겠습니다.
데이터 불러오기
import pickle
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import re
import urllib.request
!pip install konlpy
from konlpy.tag import Okt
from tqdm import tqdm
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import urllib.request
urllib.request.urlretrieve('https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt', filename = 'rating_train.txt')
urllib.request.urlretrieve('https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt', filename = 'rating_test.txt')
import pandas as pd
train_data = pd.read_table('rating_train.txt')
test_data = pd.read_table('rating_test.txt')print(len(train_data))
display(train_data.head())
print(len(test_data))
display(test_data.head())
데이터 정제하기
len(train_data), len(test_data)
train_data['label'].value_counts().plot(kind = 'bar')
train_data.groupby('label').size().reset_index(name = 'count')
train_data['label'].value_counts()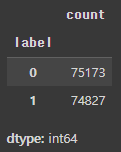
train_data[train_data['document'].isnull()]
train_data.dropna(how = 'any')
# [^ㄱ-ㅎㅏ-ㅣ가-힣 ] - 한글/공백을 제외하고 모두 제거
train_data['document'] = train_data['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ] ","", regex=True) # 정규 표현식 수행
train_data['document'] = train_data['document'].str.replace(" +"," ", regex=True) # 공백은 1개이상은 공백 1개로 변경
train_data['document'] = train_data['document'].str.replace('^ +', "", regex=True) # 공백은 empty 값으로 변경
train_data['document'].replace('', np.nan, inplace=True) # 공백은 Null 값으로 변경
train_data.dropna(how='any', inplace = True) # Null 값 제거
print('전처리 후 테스트용 샘플의 개수 :',len(train_data))
# [^ㄱ-ㅎㅏ-ㅣ가-힣 ] - 한글/공백을 제외하고 모두 제거
test_data['document'] = test_data['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ] ","", regex=True) # 정규 표현식 수행
test_data['document'] = test_data['document'].str.replace(" +"," ", regex=True) # 공백은 1개이상은 공백 1개로 변경
test_data['document'] = test_data['document'].str.replace('^ +', "", regex=True) # 공백은 empty 값으로 변경
test_data['document'].replace('', np.nan, inplace=True) # 공백은 Null 값으로 변경
test_data.dropna(how='any', inplace = True) # Null 값 제거
print('전처리 후 테스트용 샘플의 개수 :',len(test_data))
train_data.drop_duplicates(subset = ['document'], inplace=True) # document 열에서 중복인 내용이 있다면 중복 제거
print('전처리 후 학습용 샘플의 개수 :',len(train_data))
test_data.drop_duplicates(subset = ['document'], inplace=True) # document 열에서 중복인 내용이 있다면 중복 제거
print('전처리 후 테스트용 샘플의 개수 :',len(test_data))
print(train_data['document'][0])
print(test_data['document'][0])
토큰화
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
okt = Okt()
시간 많이 걸림.
x_train = []
# tqdm 사용해야, 진행사항 프로그래스바 표시됨!!
for sentence in tqdm(train_data['document']):
tokenized_sentence = okt.morphs(sentence, stem = True) # 토큰화
stopwords_removed_sentence = [word for word in tokenized_sentence if not word in stopwords] # 불용어 제거
x_train.append(stopwords_removed_sentence)x_train[:3]
x_test = []
for sentence in tqdm(test_data['document']):
tokenized_sentence = okt.morphs(sentence, stem = True) # 토큰화
stopwords_removed_sentence = [word for word in tokenized_sentence if not word in stopwords] # 불용어 제거
x_test.append(stopwords_removed_sentence)
x_test[:3]
전처리 데이터 저장
with open(rootdir + 'x_train_nmovie.pickle', 'wb') as handle:
pickle.dump(x_train, handle)
with open(rootdir + 'x_test_nmovie.pickle', 'wb') as handle:
pickle.dump(x_test, handle)
전처리 데이터 불러오기
with open(rootdir + 'x_train_nmovie.pickle', 'rb') as handle:
x_train = pickle.load(handle)
with open(rootdir + 'x_test_nmovie.pickle', 'rb') as handle:
x_test = pickle.load(handle)len(x_train), len(x_test)
정수 인코딩
기계가 텍스트를 숫자로 처리할 수 있도록 훈련데이터와 테스트데이터에 정수 인코딩을 수행해야 합니다.
- 우선, 훈련 데이터에 대해서 단어집합(vocaburary)을 만들어 봅시다.
tokenizer = Tokenizer()
tokenizer.fit_on_texts(x_train)
단어집합이 생성되는 동시에 각 단어에 고유한 정수가 부여되었습니다.
- 이는 tokenizer.word_index 를 출력하여 확인 가능합니다.
print(tokenizer.word_index)
print(len(tokenizer.word_index))
단어가 43,000 개가 넘게 존재합니다.
- 각 정수는 전체 훈련데이터에서 등장 빈도 수가 높은 순서대로 부여되었기 때문에
- 높은 정수가 부여된 단어들은 등장 빈도 수가 매우 낮다는 것을 의미합니다. 여기서는 빈도수가 낮은 단어들은 자연어 처리에서 배제하고자합니다.
- 등장 빈도수가 3회 미만인 단어들이 이 데이터에서 얼만큼의 비중을 차지하는지 확인해 봅시다.
threshold = 3
total_cnt = len(tokenizer.word_index) # 단어의 수
rare_cnt = 0 # 등장 빈도수가 threshold 보다 작은 단어의 개수를 카운트
total_freq = 0 # 훈련 데이터의 전체 단어 빈도수 총 합
rare_freq = 0 # 등장 빈도수가 threshold 보다 작은 단어의 등장 빈도수 총합
# 단어와 빈도수의 쌍(pair)을 key와 value로 받는다.
for key, value in tokenizer.word_counts.items():
total_freq = total_freq + value
# 단어의 등장 빈도수가 threshold 보다 작으면
if (value < threshold):
rare_cnt = rare_cnt + 1
rare_freq = rare_freq + value
print('단어 집합(vocabulary)의 크기 :', total_cnt)
print('등장 빈도가 %s번 이하인 희귀 단어의 수: %s'%(threshold - 1, rare_cnt))
print('단어 집합에서 희귀 단어의 비율 : ', (rare_cnt / total_cnt) * 100)
print('전체 등장 빈도에서 희귀 단어 등장 빈도 비율 : ', (rare_freq / total_freq) * 100)
- 등장 빈도가 threashold 값인 3회 미만, 즉 2회 이하인 단어들은 단어 집합에서 무려 절반 이상인 58.7%를 차지합니다.
- 하지만, 실제로 훈련 데이터에서 등장 빈도로 차지하는 비중은 상대적으로 매우 적은 수치인 2% 밖에 되지 않습니다.
- 등장 빈도가 2회 이하인 단어들은 자연어 처리에서 별로 중요하지 않을 듯 합니다.
- 그래서 이 단어들은 정수인코딩 과정에서 배제시키겠습니다.
등장 빈도수가 2 이하인 단어들의 수를 제외한 단어의 개수를 단어 집합의 최대 크기로 제한하겠습니다.
# 전체 단어 개수 중, 빈도수 2 이하인 단어는 제거
# 0번 패딩 토큰을 고려하여 + 1
vovab_size = total_cnt - rare_cnt + 1
print('단어 집합의 크기 :', vovab_size)
단어 집합의 크기는 20,669개 입니다. 이를 keras의 tokenizer의 인자로 넘겨주고, 텍스트 시퀀스를 정수 시퀀스로 변환합니다.
tokenizer = Tokenizer(vovab_size)
tokenizer.fit_on_texts(x_train)
x_train = tokenizer.texts_to_sequences(x_train)
x_test = tokenizer.texts_to_sequences(x_test)len(x_train), len(x_test)
print(x_train[:3])
각 샘플내의 단어들은 각 단어에 대한 정수로 변환된 것을 확인할 수 있습니다.
- 단어의 개수는 20,669개로 제한되었으므로, 0번 단어 ~ 20,558번 단어 까지만 사용중입니다.
- 0번 단어는 패딩을 위한 토큰 임을 상기합시다.
train_data 에서 y_train 과 y_test를 별도로 저장해줍니다.
y_train = np.array(train_data['label'])
y_test = np.array(test_data['label'])print(y_train[:10])
print(y_test[:10])
빈 샘플(empty samples) 제거
- 전체 데이터에서 빈도수가 낮은 단어가 삭제되었다는 것은 빈도수가 낮은 단어만으로 구성되었던 샘플들은 빈(empty) 샘플이 되었다는 것을 의미합니다.
- 빈 샘플들은 어떤 레이블이 붙어있던 의미가 없으므로 빈 샘플들을 제거해주는 작업을 하겠습니다.
- 각 샘플들의 길이를 확인해서 길이가 0인 샘플들의 인덱스를 받아오겠습니다.
# 빈 배열 찾기 '[]'
drop_train = [index for index, sentence in enumerate(x_train) if len(sentence) < 1]len(drop_train)
drop_train[:5]
x_train[28], x_train[412]
print(len(x_train))
print(len(y_train))
# 빈 샘플들을 제거
for index in reversed(drop_train):
del x_train[index]
del y_train[index]print(len(x_train))
print(len(y_train))
145,733 개로 샘플의 수가 줄어든 것을 확인할 수 있습니다.
패딩
- 서로 다른 길이의 샘플들의 길이를 동일하게 맞춰주는 패딩 작업을 진행해보겠습니다.
- 전체 데이터에서 가장 길이가 긴 리뷰와 전체 데이터의 길이 분포를 알아보겠습니다.
print('리뷰의 최대 길이 :', max(len(l) for l in x_train))
print('리뷰의 평균 길이 :', sum(map(len, x_train)) / len(x_train))
plt.hist([len(review) for review in x_train], bins = 50)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()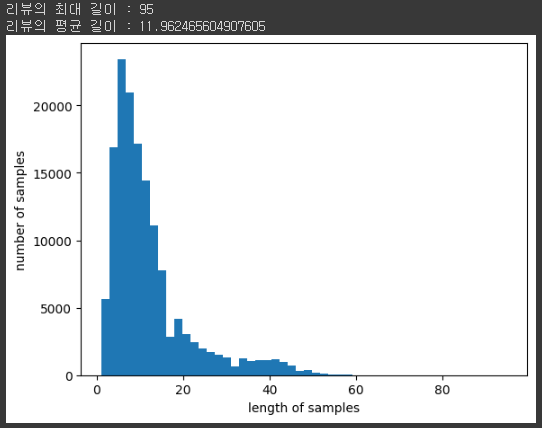
가장 긴 리뷰의 길이는 95이며, 그래프를 봤을때 전체 데이터의 길이 분포는 대체적으로 약 11내외의 길이를 가지는 것을 볼 수 있습니다.
- 모델이 처리할 수 있도록 x_train과 x_test의 모든 샘플의 길이를 특정 길이로 동일하게 맞춰줄 필요가 있습니다.
- 특정 길이 변수를 max_len으로 정합니다.
- 대부분의 리뷰가 내용이 잘리지 않도록 할 수 있는 최적의 max_len 의 값은 몇일까요?
- 전체 샘플 중 길이가 max_len 이하인 샘플의 비율이 몇 % 인지 확인하는 함수를 만듭니다.
def below_threshold_len(max_len, nested_list):
count = 0
for sentence in nested_list:
if (len(sentence) <= max_len):
count = count + 1
print('전체 샘플 중 길이가 %s 이하인 샘플의 비율: %s'%(max_len, (count / len(nested_list)) * 100))위의 분포 그래프를 봤을때, max_len = 30 이 적당할 것 같습니다.
- 이 값이 얼마나 많은 리뷰의 길이를 커버하는지 확인해 봅니다.
max_len = 30
below_threshold_len(max_len, x_train)
전체 훈련 데이터 중 약 93%의 리뷰가 30이하의 길이를 가지는 것을 확인했습니다.
- 모든 샘플의 길이를 30으로 맞추겠습니다.
x_train_pad = pad_sequences(x_train, maxlen = max_len)
x_test_pad = pad_sequences(x_test, maxlen = max_len)x_train_pad.shape, x_test_pad.shape
모델링 (Feat. LSTM)
하이퍼 파라미터인 임베딩벡터의 차원은 100, 은닉상태의 크기는 128 입니다.
- 모델은 다 대 일 구조의 LSTM을 사용합니다.
- 해당 모델은 마지막 시점에서 두 개의 선택지 중 하나를 예측하는 이진 분류 문제를 수행하는 모델입니다.
- 이진 분류 문제의 경우, 출력 층에 로지스틱 회귀를 사용해야 하므로 활성화 함수로는 시그모이드 함수를 사용하고, 손실함수로는 크로스 엔트로피 함수를 사용합니다.
- 하이퍼 파라미터인 배치 크기는 64이며, 15 epoch 을 수행합니다.
하드웨어 자원부족으로 1회만 학습하였습니다
from tensorflow.keras.layers import Input, Embedding, Dense, LSTM
from tensorflow.keras.models import Sequential
from tensorflow.keras.models import load_model
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
embedding_dim = 100 # 단어 임베딩 벡터의 출력 차원 (결과로서 나오는 임베딩 벡터의 크기)
hidden_units = 128
model = Sequential()
# 30 : 입력 시퀀스의 길이
model.add(Input(shape = (30,)))
# vocab_size : 20669 - 딕셔너리의 단어수 (유일한 단어수)
model.add(Embedding(vocab_size, embedding_dim))
model.add(LSTM(hidden_units))
model.add(Dense(1, activation = 'sigmoid'))
model.summary()
esc = EarlyStopping(monitor = 'val_loss', patience = 4)
chk = ModelCheckpoint(filepath = rootdir + 'n_movie_model.keras', monitor = 'val_loss', save_best_only = True, verbose = 1)
model.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
model.fit(x_train_pad, y_train, validation_data = (x_test_pad, y_test), epochs = 1)#, callbacks= [esc, chk])
리뷰 예측하기
def sentiment_predict(new_sentence):
new_sentence = re.sub(r'[^ㄱ-ㅎㅏ-ㅣ가-힣 ]','', new_sentence)
new_sentence = okt.morphs(new_sentence, stem=True) # 토큰화
new_sentence = [word for word in new_sentence if not word in stopwords] # 불용어 제거
encoded = tokenizer.texts_to_sequences([new_sentence]) # 정수 인코딩
pad_new = pad_sequences(encoded, maxlen = max_len) # 패딩
score = float(model.predict(pad_new)) # 예측
if (score > 0.5):
print("{:.2f}% 확률로 긍정 리뷰입니다.\n".format(score * 100))
else:
print("{:.2f}% 확률로 부정 리뷰입니다.\n".format((1 - score) * 100))sentiment_predict('이 영화 개꿀잼 ㅋㅋㅋ')
sentiment_predict('이 영화 핵노잼 ㅠㅠ')
모델 불러오기
모델을 저장 시 불러와서 사용할 수도 있습니다.
from tensorflow.keras.models import load_model
loaded_model = load_model(rootdir + 'n_movie_model.keras')
print("\n 테스트 정확도: %.4f" % (loaded_model.evaluate(x_test, y_test)[1]))
끝~

'AI Tutorial' 카테고리의 다른 글
| [Python] 동일 폴더의 Excel 파일 모두 합치기 (1) | 2024.10.16 |
|---|---|
| [사전학습] ObjectDetection (Feat. efficientdet, OpenCV) (1) | 2024.09.04 |
| [텍스트마이닝] 이란? (0) | 2024.09.03 |
| [Python] 전이학습(Transfer Learning) 설명 (0) | 2024.08.29 |
| [Python] 오토인코더(AutoEncoder) 설명 및 코드구현 (Feat. Tensorflow) (1) | 2024.08.28 |



